Quant on Serverless: Building Institutional Portfolio Analytics Without a Compute Backbone
By Neonvil Team | 2026-05-08
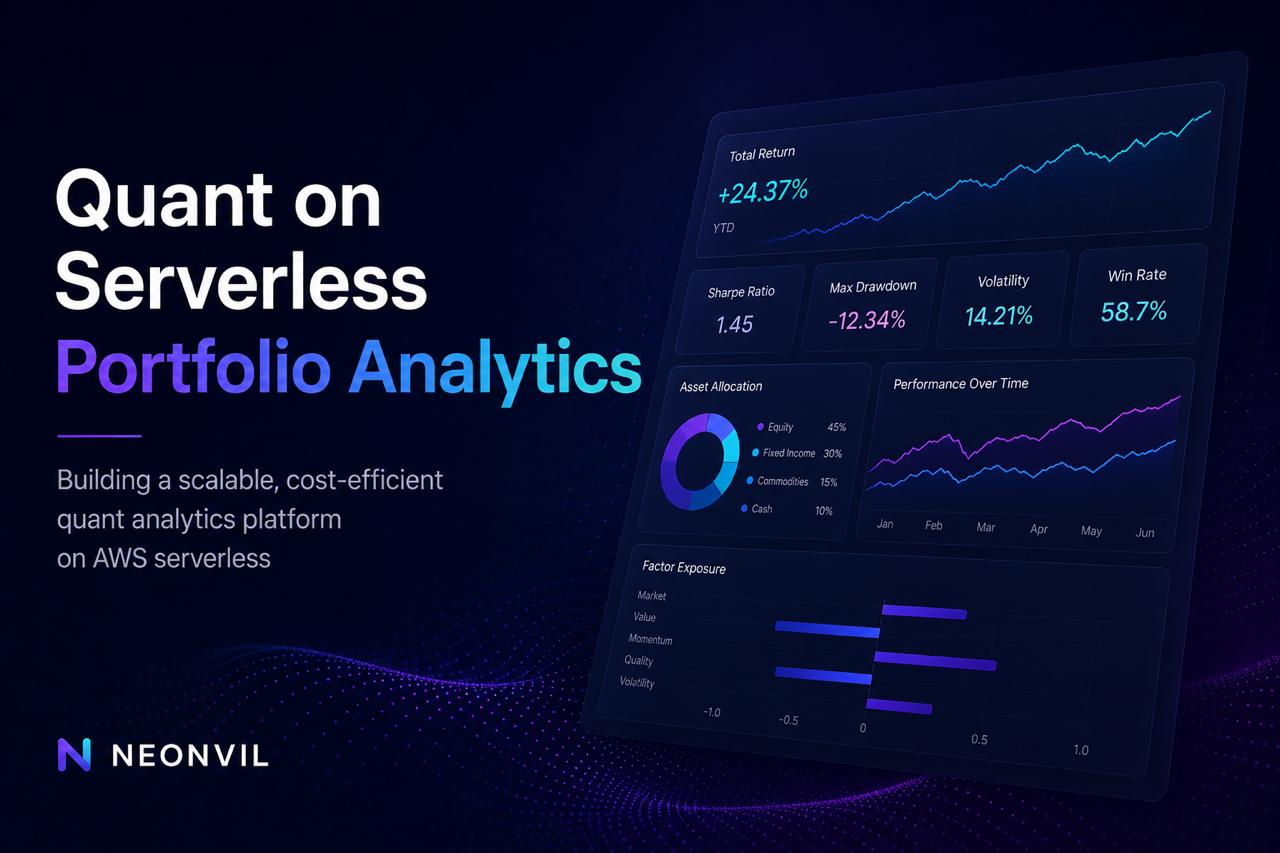
When a confidential FinTech client asked us to build an institutional portfolio analytics platform — Brinson attribution, CVaR optimization, multi-horizon risk modelling — the constraint that shaped every decision was simple: there is no dedicated compute backbone.
No big data centre. No persistent worker pool. No queue. Just three serverless services and a browser.
This post walks through the architecture we shipped to production: a React 19 SPA that runs statistical computation locally, a Node.js Azure Functions API that owns persistence and auth, and a Python service that handles the math.
The three services
Frontend SPA — React 19 + Vite + Zustand + IndexedDB. Four analytics modules — portfolio management, asset allocation modelling, backtesting, and attribution — all running offline-first. IndexedDB persists state across sessions; concurrent rendering keeps charts and matrix recalculations from blocking user interaction. Statistical work like normal CDF, inverse CDF, covariance matrices, and multi-horizon risk happens in the browser, memoized aggressively.
Backend API — Node.js on Azure Functions, PostgreSQL via Prisma. Endpoints across six bounded contexts: portfolio, allocation, backtesting, attribution, ticker search, and Yahoo Finance ingestion. Workspace-scoped multi-tenant isolation via Azure AD. The full institutional fund-statistics suite: Sharpe, Sortino, alpha, beta, max drawdown, volatility, annualised return, cumulative return.
Optimization Service — Python + SciPy SLSQP. Five strategies: MVO (Sharpe maximization), Information Ratio, CVaR, Risk Parity, and Custom weights. CVaR is a Monte Carlo bootstrap at 3,000 resamples at 1% alpha — every invocation cold, no persistent worker. Dynamic risk-free rate via SHV ETF. Constraint system: long-only, fully-invested, 30% max weight per asset.
Four engineering challenges
1. Serverless cold-start connection exhaustion
Every cold Azure Function invocation can spin up a new Prisma client, and at scale that exhausts PostgreSQL connections fast. The fix: a singleton Prisma client with warm-instance detection that survives across invocations on the same instance, and lets the cold ones initialize fresh without redundant overhead.
2. Yahoo Finance rate limits
Concurrent price fetches across many tickers hit Yahoo's 429 ceiling instantly. We wrote a custom concurrency limiter — 10 parallel requests, 30-second per-ticker timeout, per-ticker fallback — that stays under the limit while completing a full multi-ticker portfolio refresh in seconds.
3. CVaR optimization in a stateless context
A 3,000-resample Monte Carlo bootstrap at 1% alpha is computationally expensive, and on stateless Azure Functions every invocation starts cold. There is no persistent worker pool to warm up. We accepted that constraint, sized the function memory and timeout to the 3,000-sample workload, and made every invocation independent — no shared state, no warm-up assumptions.
4. In-browser probability modelling
The frontend runs probability modelling — normal CDF, inverse CDF, covariance matrices, multi-horizon risk — without a dedicated math backend. The trick is memoization: every expensive computation cached on its inputs, recomputed only when those inputs change. The UI stays responsive even when a user is scrubbing through a multi-decade risk simulation.
Why each technology
- React 19 + Vite — concurrent rendering keeps the UI responsive while heavy computations run; Vite's fast HMR makes iterative quant work tolerable.
- Node.js / Azure Functions — pay-per-invocation backend with no idle infrastructure between trading sessions.
- Python + SciPy — there is no practical equivalent of SciPy's numerical stack in JavaScript. The mathematical core had to live in Python.
- PostgreSQL + Prisma — ACID guarantees on financial records; relational integrity across portfolio hierarchies and historical snapshots, with type-safe schema migrations across the Node.js layer.
- Azure — Azure AD provides the multi-tenant identity backbone, and managed services keep ops overhead minimal for a lean team.
What we would take away
The most interesting decision was not the stack. It was accepting the absence of a compute backbone as a design constraint instead of a problem to fix.
If you assume you will have a long-running worker, your architecture quietly leans on it: caches that warm up, queues that batch, processes that hold connections. Take that away, and you find out which parts of your system genuinely need it (CVaR Monte Carlo: yes, somewhat) and which parts you only assumed needed it (everything else: no, actually).
The platform runs in production today. The browser stays responsive. Three services scale independently. Trading-session traffic spikes elastically; off-hours billing rounds to almost nothing.